Si trabajas en SEO, Screaming Frog es probablemente la herramienta que más vas a usar en tu día a día. Es un crawler de escritorio que analiza tu sitio web como lo haría Google: recorre cada URL, revisa los títulos, las meta descriptions, los encabezados, los enlaces, las imágenes y decenas de factores técnicos que afectan tu posicionamiento.
Lo que vas a aprender
- Cómo instalar, configurar y ejecutar tu primer rastreo.
- Cómo interpretar cada pestaña de análisis.
- Cómo detectar errores técnicos, de contenido y de enlazado.
- Cómo configurar el crawler para sitios grandes (+10K URLs).
- Workflow profesional: de la auditoría a la hoja de ruta SEO.
¿Qué es Screaming Frog y para qué sirve?
Screaming Frog SEO Spider es un programa de escritorio que rastrea sitios web imitando el comportamiento de un bot de búsqueda. A diferencia de herramientas en la nube como Ahrefs o Semrush, Screaming Frog se instala en tu computador y ejecuta el rastreo desde ahí, lo que te da control total sobre la velocidad, profundidad y configuración.
La versión gratuita permite rastrear hasta 500 URLs, suficiente para sitios de PYMEs y negocios medianos. La licencia de pago (£259/año) elimina ese límite y desbloquea funciones avanzadas como extracción personalizada, integraciones con Google Analytics y Search Console, y rastreo programado.
¿Para qué lo uso como consultor SEO para ecommerce? Para absolutamente todo el SEO técnico: detectar errores de rastreo, analizar la arquitectura del sitio, auditar el contenido on-page, revisar el enlazado interno y el flujo de link juice, validar migraciones y encontrar oportunidades de optimización que las herramientas online no detectan.
Puedes descargarlo gratis desde screamingfrog.co.uk. Si buscas una referencia rápida, tengo una guía básica de Screaming Frog. La instalación es directa: descarga el archivo, ejecuta el instalador y listo.
Conoce la interfaz de Screaming Frog
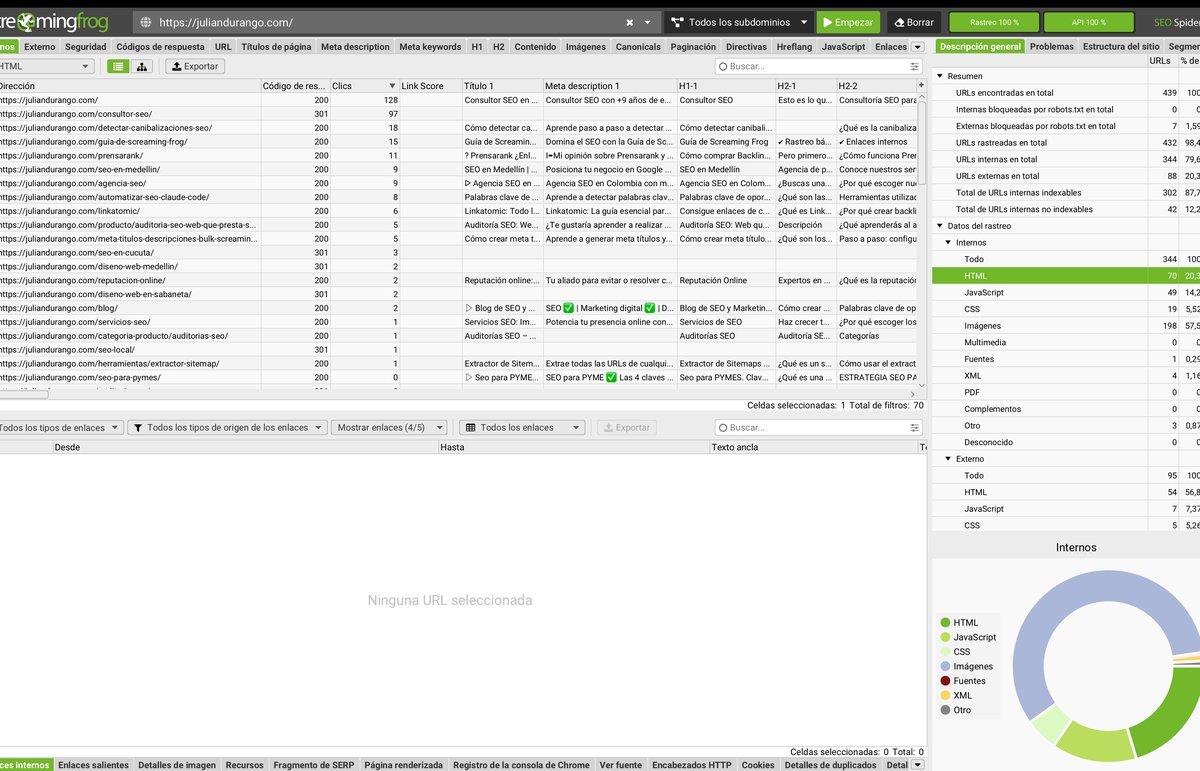
Antes de lanzar tu primer rastreo, necesitas entender las 5 zonas principales de la interfaz:
- Barra de URL. Arriba del todo. Aquí ingresas la dirección del sitio que quieres rastrear y presionas Empezar.
- Pestañas de análisis. La fila horizontal debajo de la barra. Cada pestaña (Internos, Externos, Códigos de respuesta, Títulos, Meta descriptions, H1, H2, Imágenes, Canonicals, Directivas, Hreflang) agrupa un tipo de dato.
- Tabla de resultados. El área central que ocupa la mayor parte de la pantalla. Lista cada URL con todas sus métricas en columnas.
- Panel de resumen (derecha). Descripción general con totales, datos del rastreo y estadísticas por tipo de contenido.
- Panel inferior. Detalle de la URL seleccionada: enlaces internos, enlaces salientes, detalles de imagen, fragmento de SERP, vista de código fuente.
Cómo configurar Screaming Frog antes de rastrear
La configuración por defecto funciona bien para la mayoría de sitios, pero si quieres resultados óptimos necesitas ajustar algunos parámetros antes de iniciar el rastreo. Todo se encuentra en el menú Configuración.
Configuración del Spider
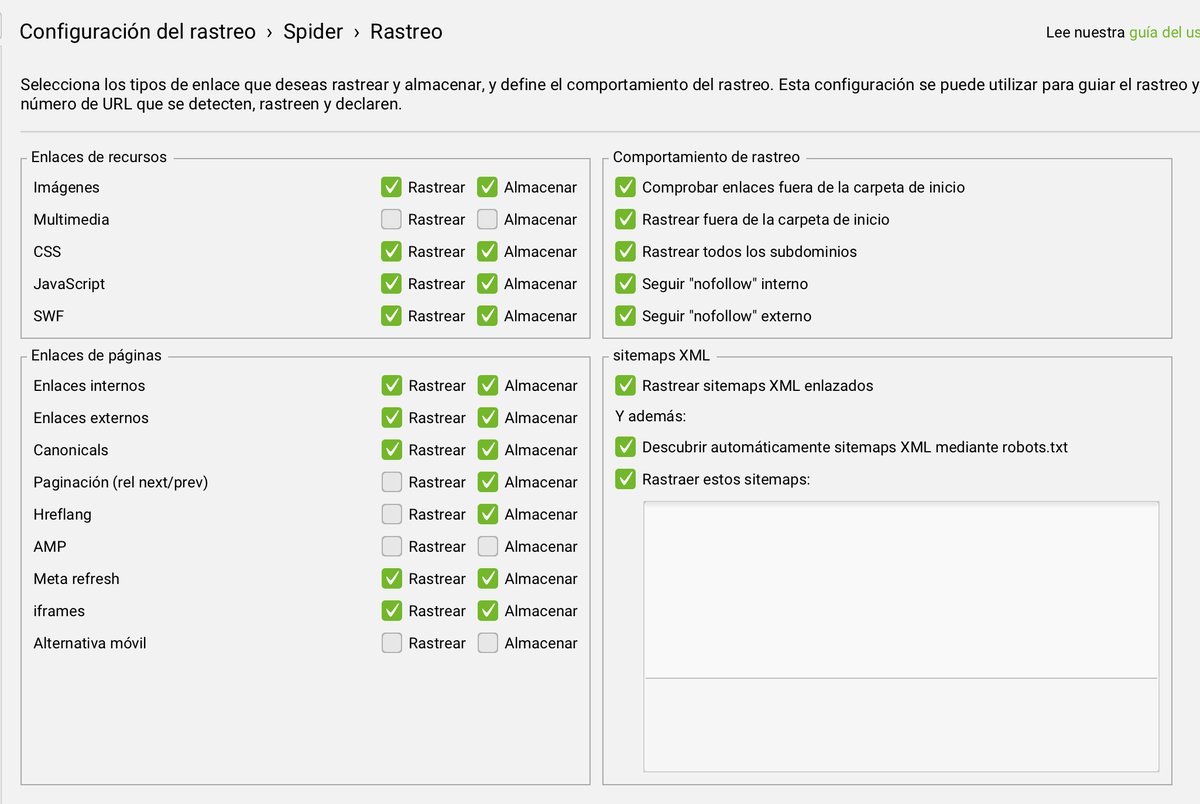
En Configuración → Spider defines qué elementos debe rastrear:
- Rastrear enlaces internos: activado (fundamental).
- Rastrear enlaces externos: activado (para detectar enlaces rotos salientes).
- Rastrear imágenes: activado (para auditar alt text y tamaño).
- Rastrear CSS/JS: activado si necesitas auditar renderizado.
- Rastrear hreflang: activado solo para sitios multiidioma.
Si tu sitio usa JavaScript pesado (React, Angular, Vue), activa el renderizado JavaScript en la pestaña “Rendering” dentro de Spider.
Velocidad de rastreo
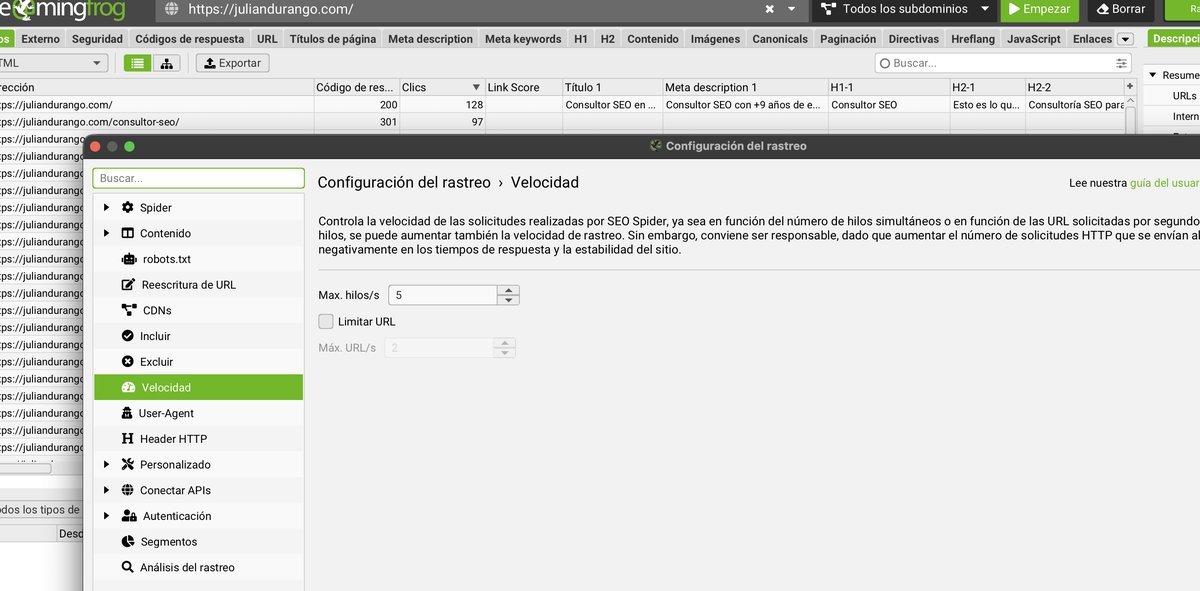
En Configuración → Velocidad controlas cuántas solicitudes simultáneas hace el crawler:
| Escenario | Configuración |
|---|---|
| Sitio propio o con permiso | 5-10 hilos simultáneos. Sin límite de URLs. |
| Sitio de un cliente | 2-5 hilos. Activa “Limitar URL” si tiene +50K páginas. |
| Servidor compartido o débil | 1-2 hilos. Reduce para no tumbar el sitio. |
User-Agent
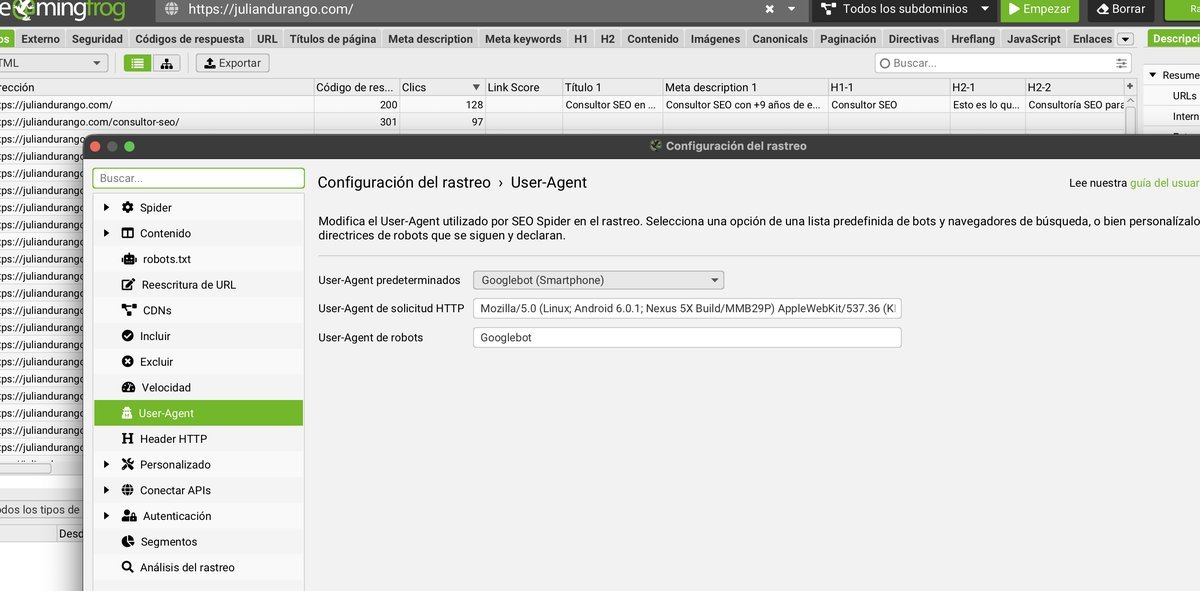
En Configuración → User-Agent eliges cómo se identifica el crawler:
- Googlebot. Para ver exactamente lo que ve Google (opción recomendada por defecto).
- Googlebot Mobile. Para auditar la versión móvil (critical con Mobile-First Indexing).
- Chrome. Para ver lo que ve un usuario real.
- Custom. Si necesitas simular un bot específico o evadir bloqueos.
Pro tip: haz un rastreo con Googlebot Desktop y otro con Googlebot Mobile. Compara los resultados. Si hay diferencias significativas, tienes un problema de paridad mobile-desktop que puede afectar tu indexación.
Cómo ejecutar tu primer rastreo
Con la configuración lista, el proceso es simple:
- Ingresa la URL de tu sitio en la barra superior (con https://).
- Selecciona el modo de rastreo: “Todos los subdominios” para un análisis completo, o “Este subdominio” para solo www.
- Haz clic en Empezar (o presiona Enter).
- Espera a que termine. Screaming Frog mostrará el progreso en la barra inferior.
El tiempo depende del tamaño del sitio y la velocidad configurada. Un sitio de 500 páginas tarda entre 2 y 5 minutos. Uno de 50.000 puede tardar horas.
Alternativa: rastreo de lista de URLs. Si solo necesitas analizar URLs específicas, ve a Modo → Lista y pega o importa las URLs que quieras auditar. Es útil para verificar migraciones o auditar landing pages concretas.
Cómo interpretar cada pestaña de Screaming Frog
Pestaña Internos: el mapa completo de tu sitio
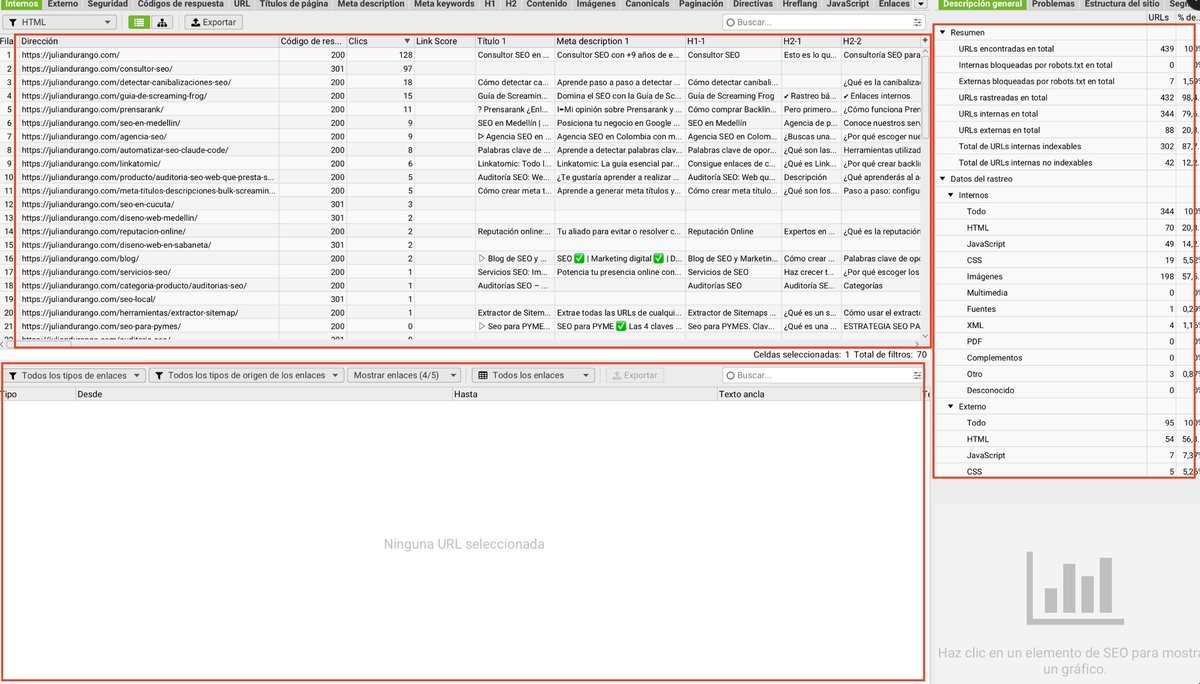
La pestaña Internos muestra todas las URLs que pertenecen a tu dominio. Es la vista principal y la que más vas a usar. Para cada URL puedes ver:
- Código de respuesta. 200 (OK), 301 (redirección), 404 (no encontrada).
- Título, H1 y Meta Description. Contenido on-page de un vistazo.
- Clics. Profundidad de rastreo (a cuántos clics del home).
- Tipo de contenido. HTML, imagen, CSS, JavaScript, PDF.
Códigos de respuesta
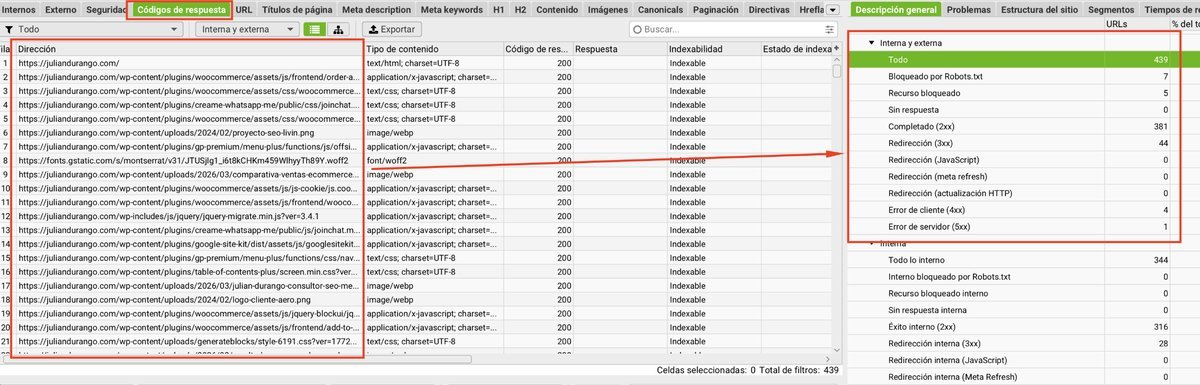
| Código | Significado |
|---|---|
| 200 OK | Todo bien. La página carga correctamente. |
| 301 Redirect | Redirección permanente. Revisa que no haya cadenas. |
| 404 Not Found | Página no encontrada. Redirige o elimina los enlaces. |
| 500 Server Error | Error del servidor. Prioridad máxima de corrección. |
Acción: exporta todas las URLs con código 3xx y 4xx. Para las 301, verifica que cada redirección apunte directamente al destino final (sin cadenas). Para las 404, identifica qué páginas las enlazan y corrige o redirige.
Títulos de página
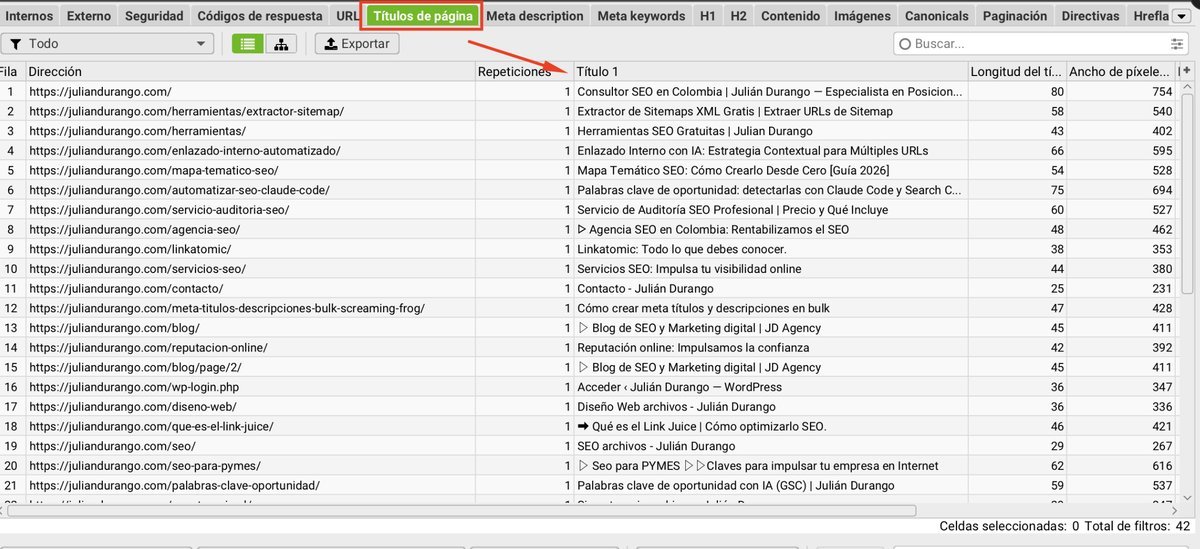
La pestaña Títulos de página te permite auditar todos los title tags de tu sitio. Detecta duplicados, vacíos, más de 60 caracteres y menos de 30 caracteres.
Meta Descriptions
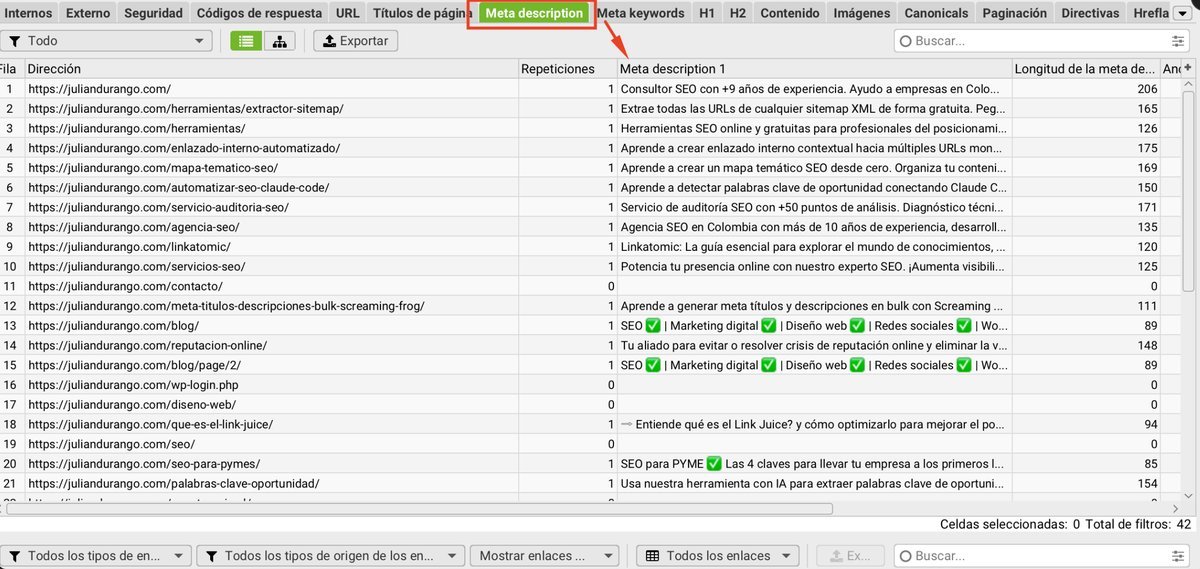
Detecta vacías, duplicadas y más de 160 caracteres. Prioriza escribir meta descriptions únicas para las páginas que más tráfico reciben.
Encabezados H1 y H2
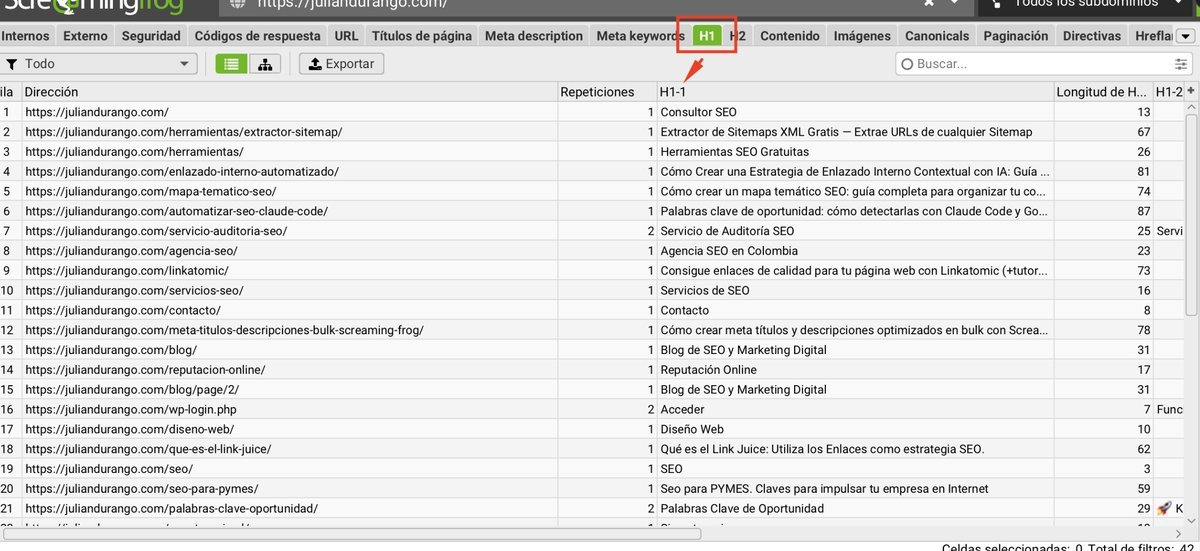
Errores comunes:
- Sin H1: cada página indexable necesita exactamente un H1.
- Múltiples H1: confunde a Google sobre el tema principal.
- H1 duplicados: mismo problema que los títulos duplicados.
- H1 ≠ Title: deberían ser similares pero no idénticos.
Imágenes y atributos alt
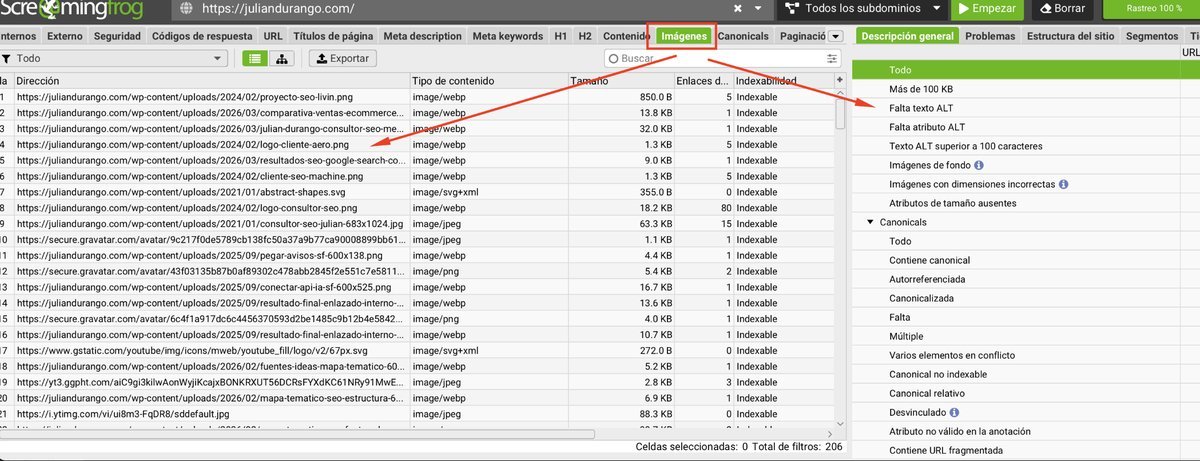
Filtra por “Missing Alt Text” y genera una lista de todas las imágenes que necesitan texto alternativo. Para las imágenes pesadas, usa ShortPixel o Imagify.
El Panel de Problemas: tu checklist de errores
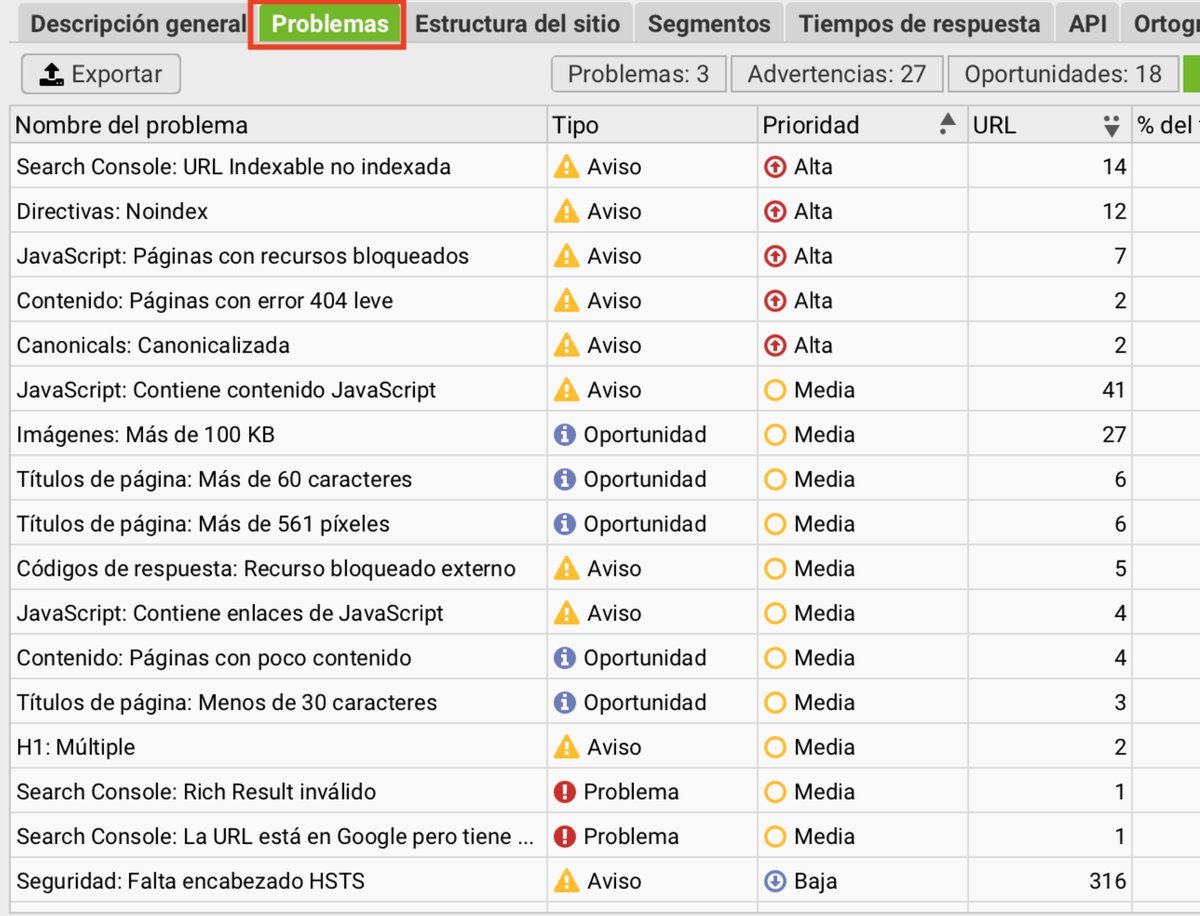
El panel Problemas (en la parte derecha) te genera automáticamente una lista de todos los errores y advertencias encontrados:
- Errores (rojo): problemas críticos que afectan la indexación.
- Advertencias (naranja): problemas que afectan el rendimiento.
- Oportunidades (azul): mejoras posibles.
Estructura del sitio
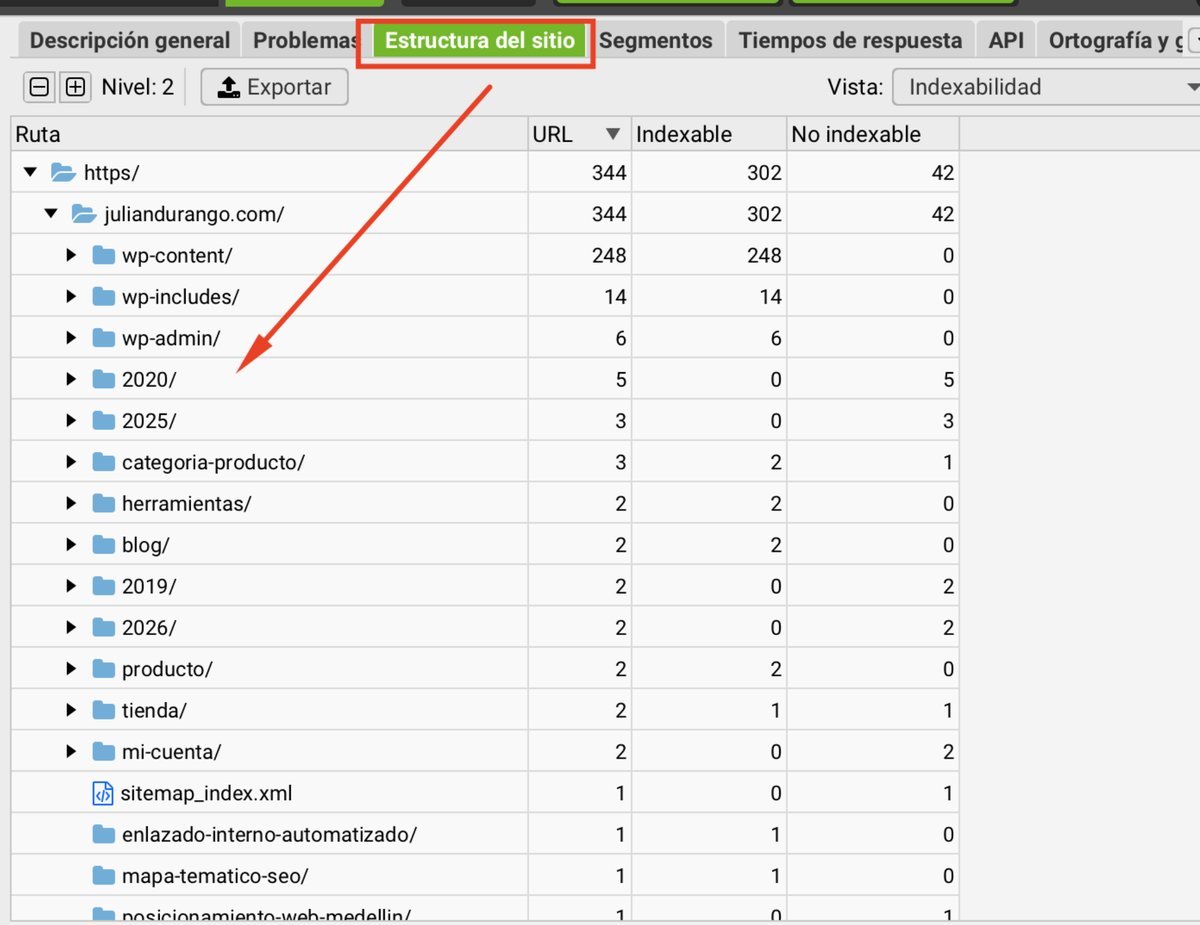
La pestaña Estructura del sitio te muestra cómo están organizadas las URLs por directorio y nivel de profundidad.
Regla general: ninguna página importante debería estar a más de 3 clics del home.
Funciones avanzadas que pocos usan
Extracción personalizada (Custom Extraction)
En Configuración → Personalizado → Extracción puedes definir selectores CSS o XPath para extraer cualquier dato de las páginas: precios, SKUs, autores, fechas de publicación, datos estructurados.
Integración con APIs externas
Screaming Frog permite conectar APIs de Google Search Console, Google Analytics 4, PageSpeed Insights e incluso modelos de Inteligencia Artificial.
Rastreo programado (Scheduling)
Puedes programar rastreos automáticos que se ejecuten diariamente, semanalmente o mensualmente.
Generación de Sitemaps XML
Screaming Frog puede generar sitemaps XML directamente desde el menú Sitemaps. Útil si necesitas un sitemap limpio que incluya solo las URLs indexables con código 200.
Cómo configurar Screaming Frog para sitios grandes (+10K URLs)
Aumentar la memoria RAM asignada
Por defecto Screaming Frog usa entre 2-4 GB de RAM. Para sitios grandes necesitas más:
- Ve a Archivo → Configuración de la aplicación → Memoria.
- Aumenta la asignación a 8-12 GB (o más si tu máquina lo permite).
- Reinicia Screaming Frog para que aplique el cambio.
Si tu equipo no tiene suficiente RAM, activa el modo de almacenamiento en base de datos desde Configuración → Spider → Almacenamiento → Base de datos.
Reducir la velocidad de rastreo
Un rastreo agresivo a un sitio grande puede sobrecargar el servidor y provocar errores 503 o bloqueos. Reduce las solicitudes simultáneas a 1-2 hilos con un intervalo de 500-1000ms entre peticiones.
Desactivar lo que no necesitas
Cada recurso que Screaming Frog rastrea consume memoria y tiempo. Para sitios grandes, desactiva lo innecesario: imágenes, CSS/JS, enlaces externos y renderizado JavaScript si no son necesarios.
Usar Incluir/Excluir para segmentar
- Incluir: limita el rastreo a una sección específica, ej:
https://sitio.com/blog/. - Excluir: bloquea secciones que no aportan, ej:
/tag/,/author/,/page/, URLs con parámetros de filtros.
Mi workflow de auditoría con Screaming Frog
- Configurar: Spider, velocidad, User-Agent según el proyecto.
- Rastrear: ejecutar crawl completo y esperar a que termine.
- Problemas: revisar panel de problemas y exportar errores.
- Priorizar: ordenar hallazgos por impacto y crear backlog.
Con toda la información, creo un backlog priorizado: primero los errores que bloquean la indexación (5xx, noindex accidental), luego las redirecciones y 404, después las mejoras de on-page (títulos, meta, H1), y finalmente las optimizaciones de velocidad y UX.
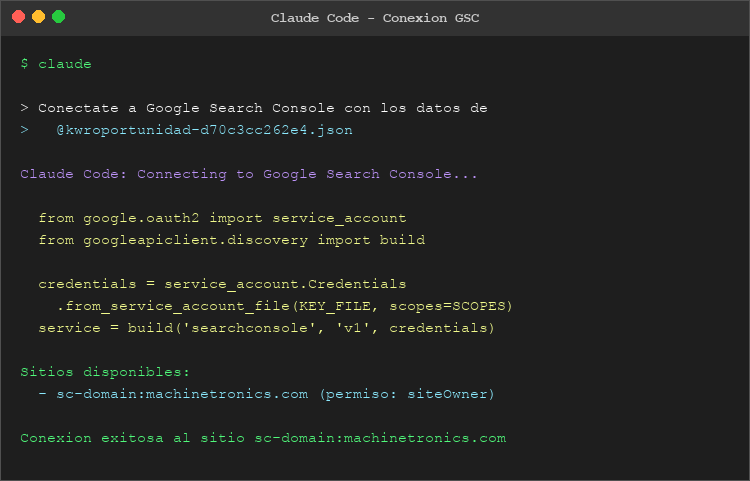
Cómo conectar las APIs en Screaming Frog
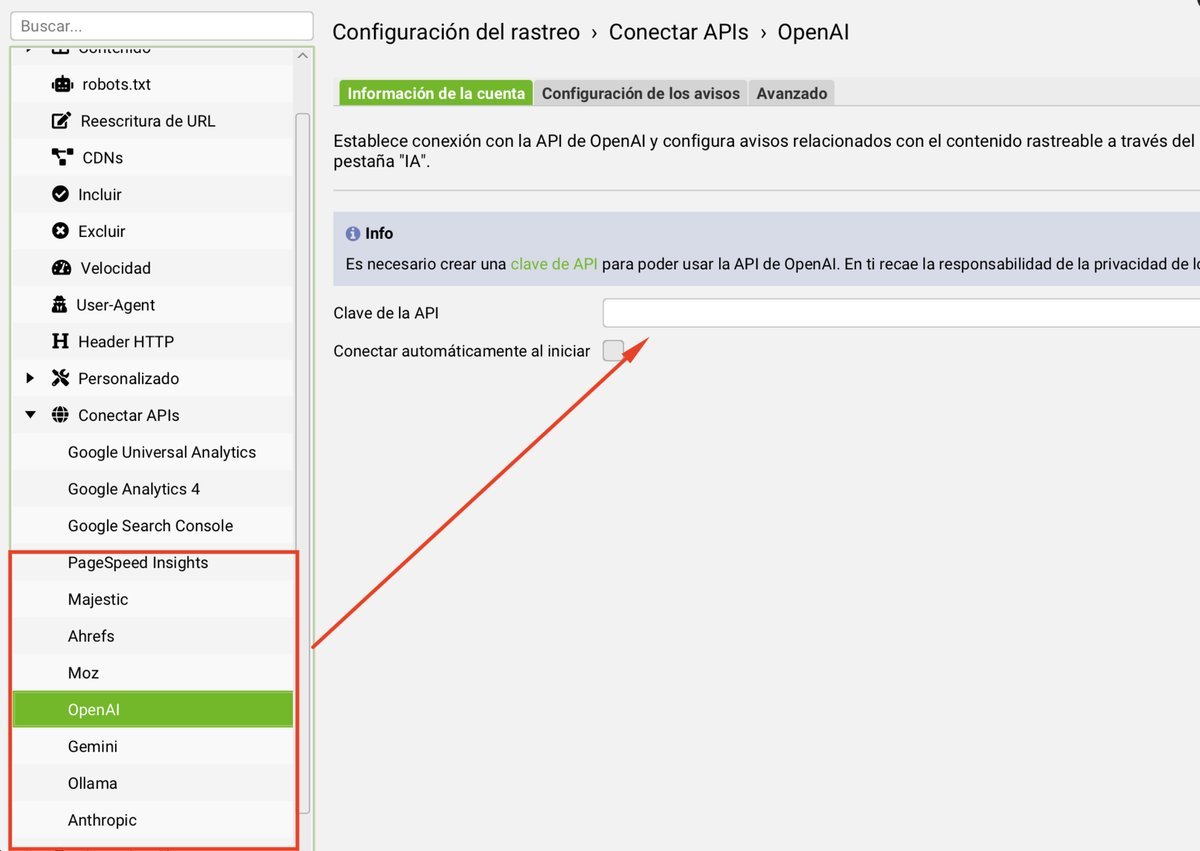
Todas las integraciones se configuran desde Configuración → Conectar APIs.
Conectar Google Search Console
- Ve a Configuración → Conectar APIs → Google Search Console.
- Haz clic en Conectar a una nueva cuenta.
- Autoriza tu cuenta de Google.
- Selecciona la propiedad (dominio) que corresponde al sitio.
- Configura el rango de fechas (últimos 3 meses para datos estables).
- Marca las dimensiones: Impresiones, Clics, CTR, Posición media.
- Haz clic en Aceptar y lanza el rastreo.
Conectar Google Analytics 4
- Ve a Configuración → Conectar APIs → Google Analytics 4.
- Conecta tu cuenta de Google.
- Selecciona la propiedad de GA4 correspondiente.
- Elige métricas: Sesiones, Usuarios, Tasa de rebote, Duración media, Conversiones.
- Configura el rango de fechas.
- Acepta y rastrea.
Conectar APIs de Inteligencia Artificial
Esta función permite conectar modelos de IA (OpenAI, Gemini, Claude) para analizar el contenido de cada página automáticamente durante el rastreo:
- Configuración → Conectar APIs → IA.
- Selecciona el proveedor y modelo.
- Ingresa tu API Key.
- Define tus prompts personalizados.
- Configura cuántas URLs quieres analizar (cuidado con los costes).
Conectar PageSpeed Insights
- Configuración → Conectar APIs → PageSpeed Insights.
- Ingresa tu API Key de Google.
- Selecciona Móvil y/o Escritorio.
- Elige métricas: LCP, FID/INP, CLS, FCP, TTFB, Speed Index.
Esta API es lenta (1-3 segundos por URL). Para sitios grandes, úsala solo en URLs importantes.
Errores comunes al usar Screaming Frog
- Rastrear sin configurar primero: tómate 2 minutos para configurar antes de lanzar.
- No filtrar los resultados: filtra por tipo de contenido, código de respuesta e indexabilidad.
- Ignorar las URLs con parámetros: URLs con parámetros pueden multiplicar tu crawl por 10.
- No guardar el rastreo: guarda siempre en Archivo → Guardar.
Screaming Frog gratis vs. de pago
Versión Gratuita (proyectos pequeños):
- Hasta 500 URLs por rastreo.
- Análisis de títulos, meta, H1, H2.
- Códigos de respuesta.
- Detección de redirecciones.
Licencia de Pago (£259/año, para profesionales):
- URLs ilimitadas.
- Extracción personalizada (CSS/XPath).
- Integración Google Analytics + GSC.
- Rastreo programado automático.
- Renderizado JavaScript.
- Comparación de rastreos.
Preguntas frecuentes sobre Screaming Frog
¿Screaming Frog es gratis?
Sí, tiene una versión gratuita que permite rastrear hasta 500 URLs. Para más funcionalidades, la licencia cuesta £259/año.
¿Cuántas URLs puede rastrear Screaming Frog?
La versión gratuita tiene límite de 500 URLs. La versión de pago no tiene límite técnico. El factor limitante es la memoria RAM.
¿Screaming Frog afecta el rendimiento de mi sitio?
Puede hacerlo si configuras demasiados hilos. Con 2-5 hilos el impacto es mínimo.
¿Cómo rastreo un sitio con JavaScript?
Configuración → Spider → Rendering y selecciona “JavaScript”.
¿Cómo exporto los datos?
Exportación en bloque → Todo. Los datos se abren en Excel o Google Sheets.
¿Puedo analizar la competencia?
Sí, puedes rastrear cualquier dominio público.